Enter password to view case study
Product Design
/
AI
/
Machine Learning
Aurora Copilot
Embedding AI into complex workflows
Overview
The copilot is not a chatbot. It's the AI layer embedded across Aurora's platform. It lives inside the workflows of brokers and underwriters, surfacing intelligence where decisions happen.
On top of which we had a highly regulated industry where we had a contstraint from day one:
For underwriters
Under FCA regulation, we can surface information but cannot provide advisement. The AI can tell an underwriter that a rebuild cost is 40% below comparable properties. It cannot say to increase it. Every piece of AI-generated copy in the platform needed to respect this boundary
For brokers
The AI can say "Rebuild cost is 40% below median for this property type." It cannot say "You should increase the rebuild cost."
the design approach
Ambient & contextual intelligence. The copilot model.
We deliberately chose "copilot" over "autopilot." The AI doesn't make decisions, it prepares the underwriter to make better ones.
We evaluated three AI interaction patterns: contextual inline suggestions, ambient insight cards, and a blank-canvas chat sidebar. We went with a combination of the second two.
year
2024 – Current
company
Aurora
role
Lead Product Designer
focus
Product Design
UX Strategy
Rapid prototyping
User testing
What was the impact so far?
STP rate
52% - 80% across 1,200+ policies
pricing overrides
0% to date
Quote rate
75–81% maintained as volume scaled 5×
the first challenge
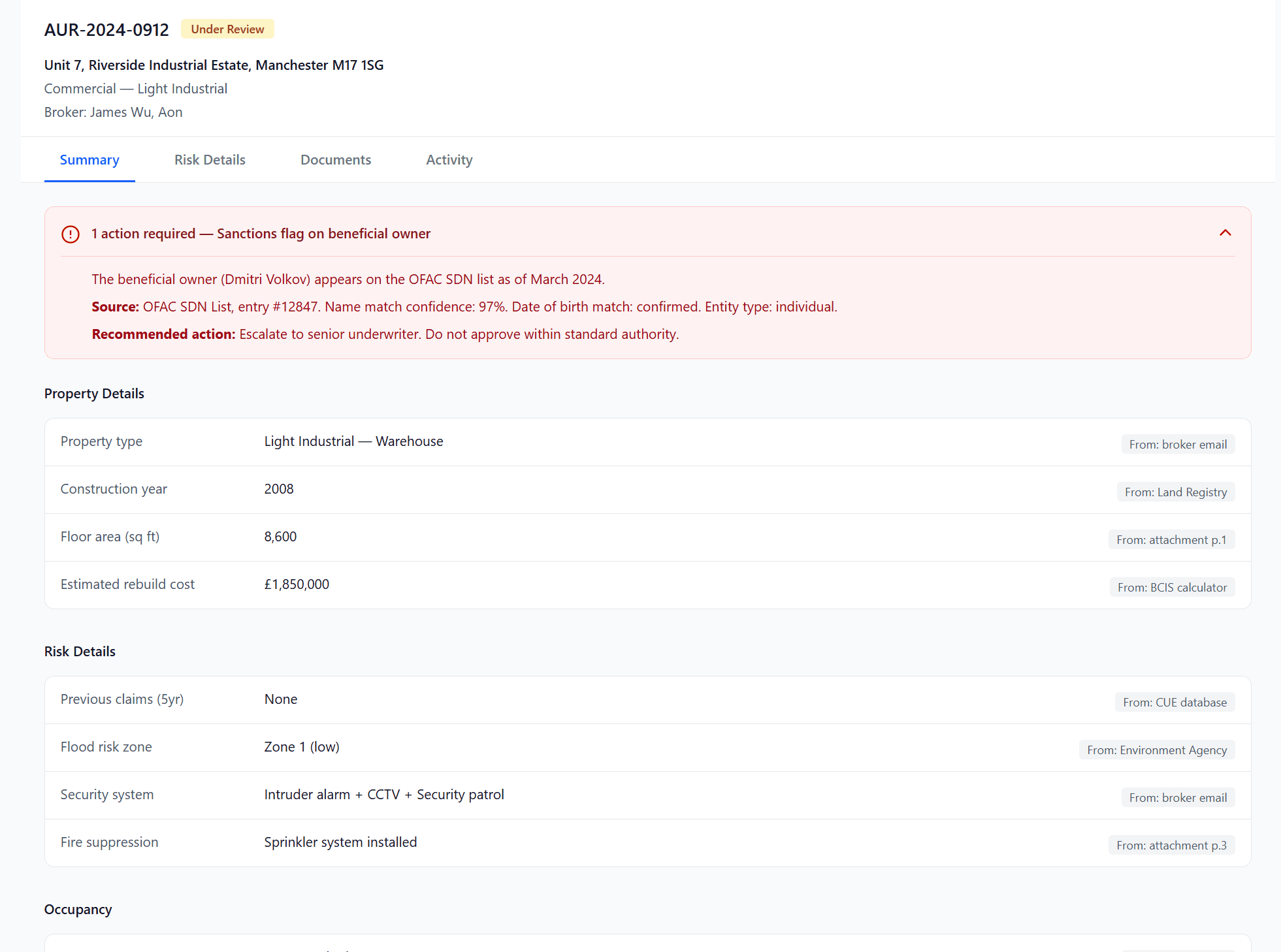
Different AI outputs need different trust mechanisms.

For brokers
How might we help a junior broker who doesn't know what questions to ask, in order to make the correct submission and avoid underinsurance, especially when it comes to complex risks like commercial property?

For underwriters
How might we make AI useful to a senior underwriter who trusts their own judgment more than any algorithm?
When I conducted user interviews with underwriters, we discovered that their attitude toward data is intuitive. They rely on experience for decisions, and data plays a supporting role. Blank-canvas conversational interfaces don't help, because underwriters work alongside submissions, evidence packs, and ongoing conversations, not in isolation.
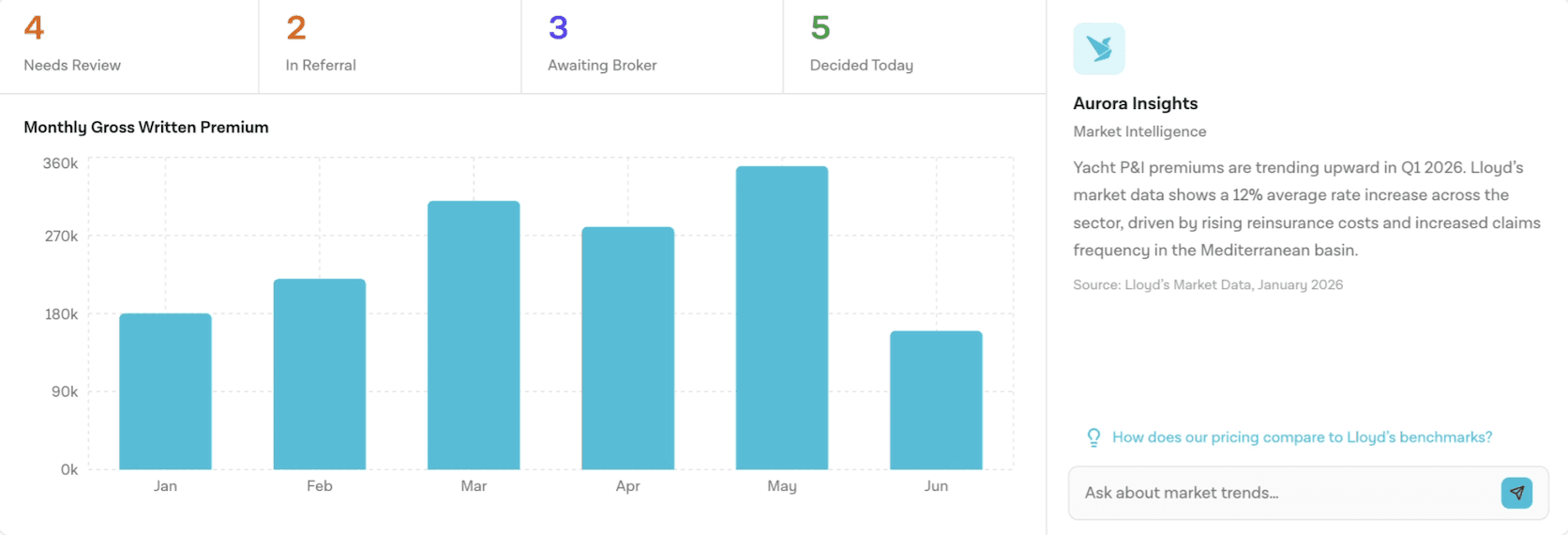
Ambient AI cards
As an underwriter, I want risk signals surfaced in context, and not buried in a separate dashboard I have to navigate to.
Ambient cards surface proactive intelligence, market trends, risk signals, portfolio alerts, alongside the user's current view, with cited sources. The user doesn't ask for it; it appears because it's relevant to what they're looking at.
Replaced chat with a tertiary link showing underwriters they could access intelligence if they wanted to. Card signals what needs attention. Deep-dive happens in the case view, where the user has already committed to investigating.
the second challenge
Confidence scores aren't enough
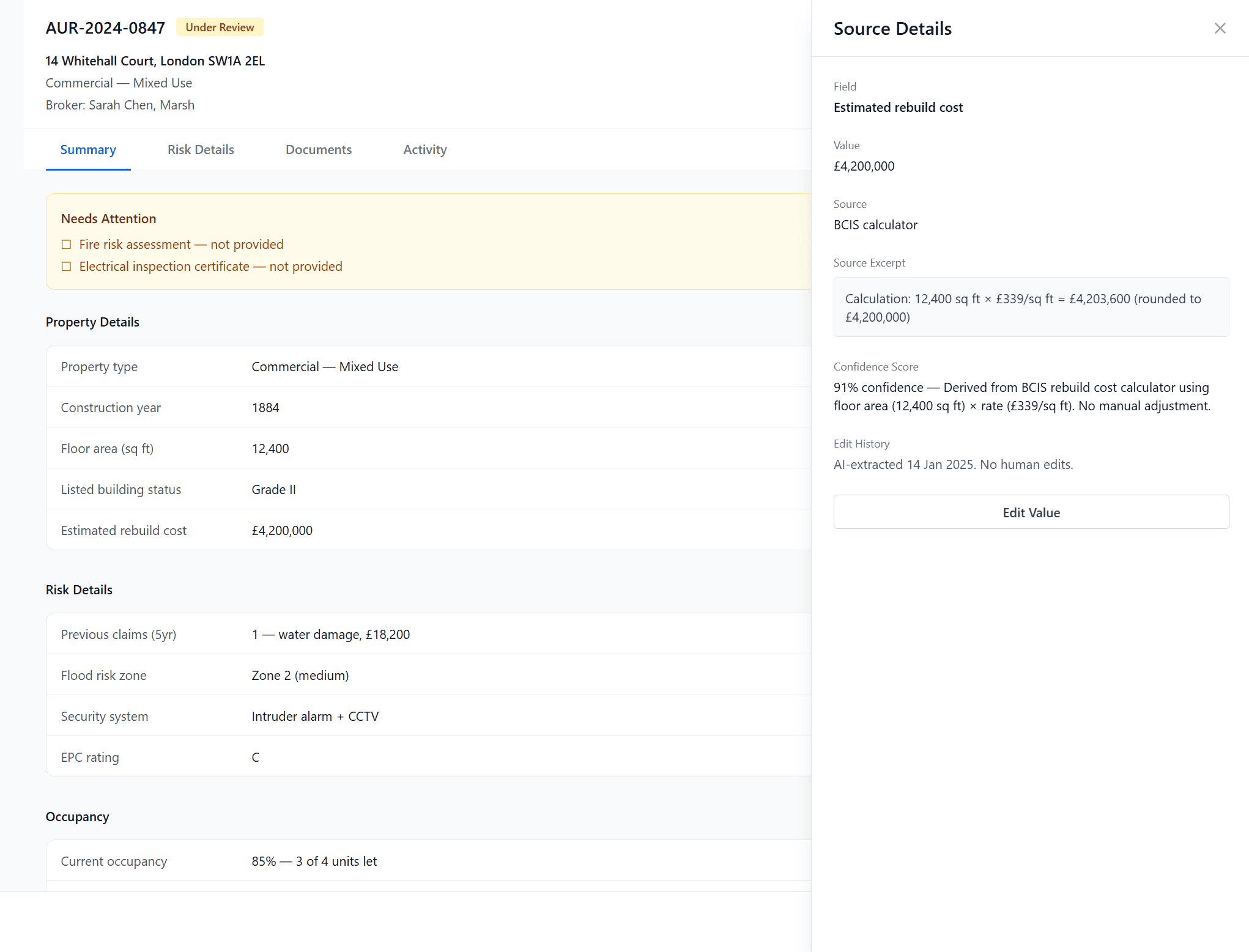
Based on the earlier test, we found that vague scorings did not test well with our target audience. They asked questions like "What does 65% mean?" or "What is high confidence?". It puts cognitive work to interpret what it means in practice, while something like "Check source" did the same work, but also makes it actionable.
Internally we also agreed that % implies a level of precision, but the model doesn't have that.
For underwriters who need auditable, defensible actions, the answer isn't better confidence scores. It's specificity.
this lead to our solution
Contextual intelligence
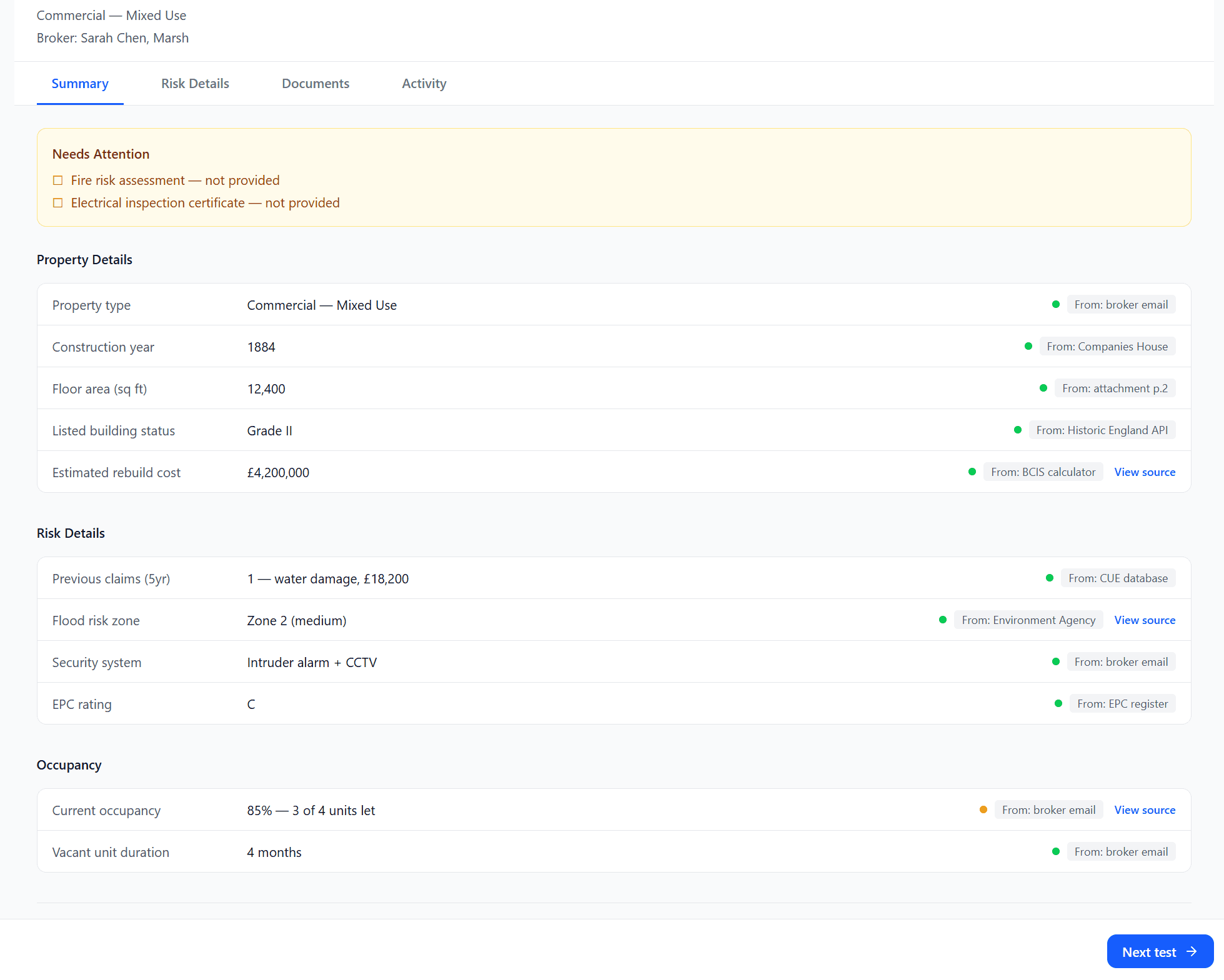
As an underwriter, I want the AI to have already identified the fields that need my attention so that I'm making decisions, not doing triage again.
Using a blank canvas chat would haveasked the UW to formulate a question before they'd even read the case. That's the wrong cognitive sequence. Instead I designed a solution to pre-populat
As an underwriter, I want to know whether the AI found a value or inferred one, because those two states require completely different actions from me.
A percentage tells the UW how confident the model is. A label tells the UW what to do next. In a regulated environment where every decision needs to be defensible, the action matters more than the score.
What I learnt
Give a human reviewer enough context to make a fast, defensible decision without starting over.
AI confidence is not the same as user confidence. Source provenance builds trust faster than any model accuracy claim.
The interface patterns for showing "why" (progressive disclosure, source links, confidence indicators) were as important as the AI model accuracy itself.
Match AI to cognitive mode. Scanning needs ambient information and links, not inputs. Case investigation needs a pre-populated briefing.
The copilot's value isn't replacing those heuristics but helping underwriters apply them to more structured, complete information faster.
Outcome
The copilot shipped a month ago as an integrated feature within the Aurora platform and is used by underwriters in their daily workflow.
Underwriter insights: 3 underwriters handling 480 quotes/month - that's 160 each, ~8/day.
So far the insights and pricing adjustment control was measured at 5% usage across one month.
Referral resolution: Referral rates by product type: Unoccupied 10%, Residential 25%, Commercial 30%, Mixed 40%. Quote rate held while volume scaled. Fewer cases bouncing back for missing data over time.
Copilot-specific metrics in active measurement: field-level correction rate, confidence calibration accuracy, broker response time, first-time completeness rate, insight engagement rate, time-to-decision with vs. without insights, preventable referral rate, resolution time per referral.